Controlling the quality of large volumes of training data is a complex and time-consuming task. In this post, we'll look into the problem of using noisy data in machine learning from an unconventional perspective - by making use of a loss function designed to mitigate the negative impact of noise on the model performance.
In the world of machine learning, data is the most vital resource. A common saying goes "garbage in, garbage out", which emphasises the enormous impact that dataset quality has on machine learning models.
Data is especially vital in the context of deep learning, where models usually need copious amounts of training examples in order to learn fairly complex functions. In one of the most influential computer vision competitions in the industry, ImageNet Large Scale Visual Recognition Challenge, now dominated by deep convolutional neural networks, the training dataset is comprised of more than a million hand-annotated images. Datasets of this size quickly become unwieldy and keeping track of their quality can be challenging. Using a loss function robust to noise may mitigate this issue by allowing for training efficient models on imperfect data, for instance with a high percentage of outliers or mislabeled samples.
In this post, we'll look into a loss function called bi-tempered logistic loss, proposed by the Google Brain team in Robust Bi-Tempered Logistic Loss Based on Bregman Divergence and test how it can be used to train machine learning classifiers robust against noisy data.
Noisy data
In pursuit of large volumes of data, it is more and more challenging to verify its quality. Oftentimes, the data is gathered automatically or semi-automatically, with limited quality control. For instance, it might come from some real-world sensors and may contain partially incorrect information due to hardware imperfections or environmental factors (like bit flips caused by cosmic rays). Other times, when data is collected or labelled manually, the source of noise may lie in human error. No human annotator is infallible, so it's reasonable to expect some degree of mislabelling. Such issues might be mitigated, for instance, by performing cross-validation, in which multiple annotators go through the same example, and the final label is selected by a majority voting or accepted only if there's a full consensus between the individual annotators. This strategy greatly reduces the chances of introducing errors to annotations, but significantly adds to the cost of labelling.
An interesting, although not so obvious, source of misinformation in data might come directly from limited human-level performance on a given task. For instance, consider the case of detecting tumours in X-Ray imaging. We might want to devise a machine learning model capable of detecting, based on an input X-Ray image, whether the patient has a tumour or not. Let's assume the training images are annotated by radiologists based solely on raw image data (so no extra tests or examinations and no retrospective labelling). In such a case, the quality of annotations is limited by human-level skill on the task at hand. If there are signs of tumours too vague or miniscule for any human to recognize, they won't be represented in the training labels. As a result, we end up with some positive samples mislabelled as negative ones, although it's not necessarily noise, as the labels couldn't be manually corrected as they require a super-human level of expertise. Although such datasets can't necessarily be called noisy, it helps to depict the importance of data expressiveness for training ML models. If the data contains misinformation stemming from human imperfection, it might be hard for models to overcome this bias.
Logistic loss
In order to understand the bi-tempered logistic loss we'll use in this post, let's recap the standard version of this loss function. Logistic loss is the most common loss function used for training binary classifiers. You can look up the exact formula and other details here. The plot below displays logistic loss responses for different network predictions:

As can be seen, the loss is zero if the response is correct (the activation value is equal to 1), and grows exponentially when the error increases, reaching its limit of infinitely large loss when the activation is equal to zero (i.e the loss is an unbounded function of error). This shape results in large errors being much more heavily penalized than relatively small ones (e.g the error for 0.45 is seven times greater than the one for 0.9).
In the context of noisy data, it's reasonable to expect that the network will produce huge errors for incorrectly labelled (i.e. noisy) data. As the majority of data annotations are correct, the network progressively learns the general function underlying the data. When encountering a mislabelled sample, a well-trained network will produce a correct label that doesn't match with the wrong annotation and causes the error to be very large. By allowing the losses in such scenarios to grow infinitely large, the training may become unstable, as the network will tend to "overreact" to such misclassifications (in extreme cases, this might lead to gradients exploding).
An important note on naming - logistic loss is the same as binary cross-entropy. Cross-entropy is a general term applicable to multiclass classification, but you might encounter the same function called logistic loss in the literature, which is not entirely correct as the logistic loss is for binary classification only. Nevertheless, to keep things simple and stay consistent with the nomenclature used by the authors of the paper, we'll use "logistic loss" for cases where there are more than two classes as well.
Softmax
Logistic loss work by comparing the expected probability distribution to the network response. In order for this to be feasible, it has to be ensured that the network outputs can be interpreted as a probability distribution over multiple classes, i.e. individual elements are from the range of [0,1] and add up to one. To meet this requirement, at the end of a typical classification network, a softmax layer is used.
Softmax is a pretty straightforward function that normalizes a vector of numbers in such a way as to conform to the aforementioned probability axioms. The normalization uses the exponential function, so it doesn't preserve relative ratios between individual elements. For the exact formula and more details, you can refer to this article.
The plots below show the results of passing a set of neuron activations through the softmax function.

Notice how all the values became positive, they sum up to 1, and the relative magnitude of each value is preserved, i.e. if a given value is the 3rd largest in the input vector, it stays at this position after the transformation. If we consider this set of 10 neurons to be an output layer of a classifier network, we can read from the second plot that the network considers the fourth class (denoted with "3") to be the most probable, with the probability of around 30%. The ninth class, with the lowest value prior to the transformation, stays the least probable.
Bi-tempered logistic loss
Bi-tempered logistic loss is a modification of the standard logistic loss. You can look up all the theoretical background and implementation details directly in the original paper. In this post, we'll stick to the practical use of this particular loss function.
The authors propose a slightly altered, parametric version of the typical logistic loss. The new function has some desirable features which make it useful for training neural networks that are more robust against noisy data. This means that imperfections in the training data don't impact the model quality as much as they would normally if the network was trained with the typical loss.
The function differs from its standard counterpart by being parametric. Under the hood, it uses parametric alternatives to the logarithm and softmax functions, called tempered logarithm and tempered exponential functions. Let's look into each of them to build an understanding of their impact on the final loss function.
Tempered logarithm
One of the functions constituting the tempered logistic loss is the tempered logarithm. This function takes a parameter that allows it to be bounded for all inputs, unlike a standard logarithm. This is vital in the context of using it in a loss function. Without it, the loss can grow infinitely large for maximum errors. We saw in the standard logistic loss that the loss value approached infinity as the error grew larger and larger.
Using the tempered version, we can set a reasonable upper bound on the loss value. The figure below depicts the tempered logarithm function for different parameter values (also called "temperatures"):

When the temperature is equal to 1, this function is the same as the standard logarithm. The plot for this particular value is depicted using a dashed black line.
We can see that for the parameter value equal to 0, the function is simply a linear one. As the value increases, the function bends more and more in the direction of the standard logarithm. The most important observation is that for all values lower than 1, the function is defined in zero. The value in this point serves as the upper bound of the loss that can be produced. Thus, by substituting the standard logarithm with its tempered version, it's possible to change the way the network behaves for large errors during training. Essentially, the model will be more robust to outliers.
Tempered exponential
The second part of the new loss function is a modification to the exponential function used in the softmax layer. As was the case with tempered log, this alternative accepts a single parameter impacting its shape.
In this scenario, the parameter allows for producing exponential functions with a "heavier tail". This bears comparison to the tempered log in which we tried to combat the issue of too high values. Here, conversely, we want to make very small values larger. This can be seen on the plot picturing the impact of the parameter value on the shape of the tempered exponential function:

For the parameter value equal to 1, the function defaults to the standard exponential function. For values larger than 1, however, the function is less steep, with a heavier tail.
The plots below show how using different temperatures impact the result of softmax transformation for the same activation vector we analysed previously.

As can be seen in the middle plot in the second row, when the parameter is set to 1, the result is the same as with the standard exponential. If we use smaller values, the difference between individual elements grows larger. The converse is true for larger values - the individual outputs are much closer. The results are somewhat expected. The steeper the function, the greater the derivative, meaning the greater the difference between the outputs for any two points.
Combining the two parts
The final bi-tempered logistic loss uses both tempered functions described above (hence the name "bi-tempered"). The modified exponential is used in the softmax layer, and the modified log to calculate the final loss.
Below, you can see the impact that these two parameters have on the function shape. The function takes two parameters. In the notation used here, the first one is for the logarithm and the second one for the exponential function.

The standard logistic loss, with both temperatures set to 1, is denoted with a dashed black line. Using bounded logarithm and heavy-tail exponential (by setting the first temperature below 1 and the second above 1) yields functions with different shapes, gradually getting flatter as the parameters diverge from their starting values of 1. Now, we'll check the impact of utilizing such differently shaped loss functions in practice by performing some experiments.
Experiments
With basic theory behind us, we can proceed to taking advantage of the bi-tempered logistic loss in training some models. We'll use TensorFlow and the implementation of the bi-tempered loss from the Google GitHub repository. Unfortunately, the implementation is not released as a stand-alone package, nor is it included in TensorFlow, so we will have to clone the code directly from its source repository.
The code below clones the repository and extracts the loss.py file containing the bi-tempered logistic loss.
git clone https://github.com/google/bi-tempered-loss.git
mv bi-tempered-loss/tensorflow/loss.py loss.py
rm -r bi-tempered-lossThe loss function can be later imported in Python with:
from loss import _internal_bi_tempered_logistic_loss as bi_tempered_logistic_lossThroughout all the experiments, we'll use Keras together with other open-source libraries and custom utility functions
contained in utils and plotting modules. The full list of imports is the following:
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications import resnet50
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.layers import Dense, Flatten, InputLayer, UpSampling2D
from tensorflow.keras.losses import CategoricalCrossentropy
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras.utils import to_categorical
from utils import generate_points, mix_cifar, mix_points, points_to_data, get_best_lr
from plotting import plot_cifar, plot_points, plot_synthetic_results, plot_cifar_results, plot_lr_finding_results
from loss import _internal_bi_tempered_logistic_loss as bi_tempered_logistic_loss
from keras_lr_finder.lr_finder import LRFinderYou can find all the code used in this post along with the list of dependencies here.
When training the models, we'll use a custom loss function defined in the following way:
class BiTemperedWrapper:
def __init__(self, t1=1., t2=1.):
self.t1 = t1
self.t2 = t2
self.cce = CategoricalCrossentropy(from_logits=True)
def __call__(self, labels, activations):
if self.t1 == 1. and self.t2 == 1.:
return self.cce(labels, activations)
return bi_tempered_logistic_loss(activations, labels, self.t1, self.t2)This wrapper will default to the standard, nonparametric loss when both values are set to 1. Otherwise, it'll call the bi-tempered alternative.
Speed
If you look into the implementation details, you might spot that calculating the output of tempered softmax requires an iterative process to ensure that the output elements add up to 1.
This is unlike the standard loss which has a much simpler formula.
Due to this, prior to training any classifiers, let's perform some speed check to get some insight on whether
substituting the standard loss to the bi-tempered logistic one may lead to any significant overhead, which could
potentially slow down the training process. We'll use timeit utility to measure the speed of calculations on 10k
random vectors of length 10.
First, let's check the performance of the standard cross-entropy loss provided with TensorFlow.
cce = CategoricalCrossentropy(from_logits=False)
%timeit cce(np.random.rand(1000, 10).astype(np.float32), np.random.rand(1000, 10).astype(np.float32))Result:
>>> 4.98 ms ± 227 µs per loop (mean ± std. dev. of 7 runs, 100 loop each)Now, the bi-tempered version:
%timeit bi_tempered_logistic_loss(np.random.rand(1000, 10).astype(np.float32), np.random.rand(1000, 10).astype(np.float32), 0.5, 2.)Output:
>>> 19.3 ms ± 751 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)As can be seen, the bi-tempered alternative is almost four times slower than its standard counterpart in this particular test (results will differ depending on multiple hardware and software factors). It's hard to say whether this will be a significant hindrance in your training cycle, but it's good to know that these two functions differ in this regard.
Noisy data
We'll perform experiments on two image datasets - one synthetic and one real-world. Noise will be artificially introduced to the data by mixing up a part of the labels.
Synthetic dataset
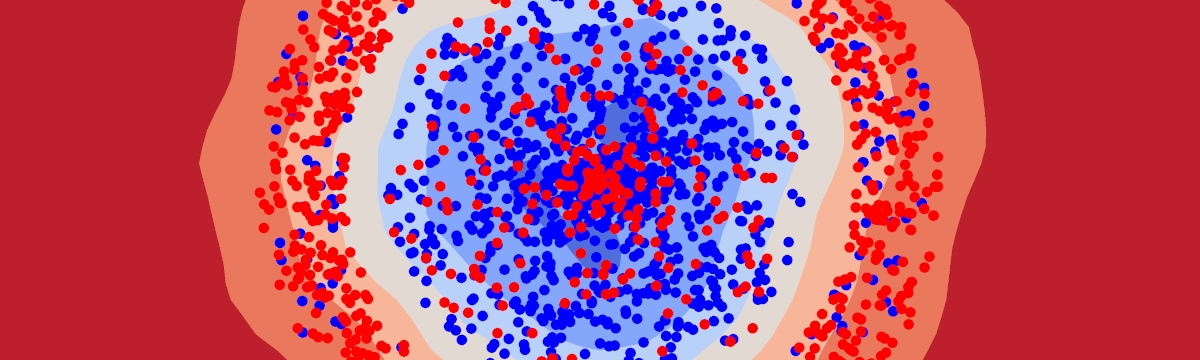
For the synthetic dataset, we'll reproduce the dataset used by the authors in the original paper. This is a simple binary classification of two-dimensional points. Such a dataset will make it possible to visualize the decision boundary predicted by the network. The dataset consists of two rings of points denoted by "blue" and "red" classes.
We'll use a simple utility function to mix up a specified percentage of the labels within a given range. This allows us to create noisy sets. We'll keep three training datasets - one noise-free, one with margin noise, and one with global noise. To create margin noise, we mix up a random 20% of labels contained near the space separating two classes of points. For global noise, 20% of random points from the whole set are mixed.
blue_train = generate_points(1200, 0, 5)
red_train = generate_points(1200, 6, 8)
blue_train_margin_noise, red_train_margin_noise = np.copy(blue_train), np.copy(red_train)
blue_train_global_noise, red_train_global_noise = np.copy(blue_train), np.copy(red_train)
mix_points(blue_train_margin_noise, red_train_margin_noise, 4, 7, 0.2)
mix_points(blue_train_global_noise, red_train_global_noise, 0, 8, 0.2)The three versions of the dataset are depicted below:

All datasets contain 2400 points, 1200 from each class.
As a validation set, we'll use a smaller dataset of 600 points without any noise:

Let's define the model with Keras Sequential API:
def synthetic_model():
return Sequential([
InputLayer(input_shape=X_train[0].shape),
Dense(32, activation='relu'),
Dense(32, activation='relu'),
Dense(2)
])This is a simple fully connected network with two hidden layers, 32 neurons each. The output layer contains two neurons as there are two classes in the dataset.
Next, we'll train a new model for each dataset and two sets of temperature values: (1.0, 1.0) (standard logistic loss)
and (0.2, 4.0) (the bi-tempered version):
datasets = {'noise free': (X_train, y_train),
'margin': (X_train_margin, y_train_margin),
'global': (X_train_global, y_train_global)}
temp_vals = [(1., 1.), (0.2, 4.0)]
results = {}
for dataset_name, (X_data, y_data) in datasets.items():
results[dataset_name] = {}
for temps in temp_vals:
results[dataset_name][temps] = {}
model = synthetic_model()
model.compile(loss=BiTemperedWrapper(*temps), optimizer=Adam(), metrics=['accuracy'])
history = model.fit(X_data, y_data, validation_data=(X_valid, y_valid), epochs=20)
results[dataset_name][temps]['model'] = model
results[dataset_name][temps]['history'] = history.historyWe save each model along with its training history.
Let's look at the performance of the models. First, the noise-free version:
plot_synthetic_results(*datasets['noise free'], results['noise free'], 'Noise free dataset')
The first two plots show the model predictions (shown as a blue-red gradient) along with the original training data. The third plot presents both training and validation accuracy for both models. We can see from the last plot that both models achieved perfect accuracy on the validation set. By investigating the exact predictions, we can see that the one trained with the bi-tempered loss produced a more defined decision boundary. At this point, it's not clear whether this is beneficial or not, as this might be a sign of overfitting to the training dataset.
Now, let's proceed to the results on the dataset with margin noise:
plot_synthetic_results(*datasets['margin'], results['margin'], '20% margin noise')
It can be observed that the decision boundary for the first model got slightly distorted. The one for the bi-tempered alternative stayed relatively unchanged. By looking at the accuracies, we can see that both models still perform almost perfectly on the validation set, and achieved about 95% accuracy on the train set. This is expected, as by mixing up 20% of margin labels, around 5% of total labels were changed. To achieve higher accuracy on the training dataset, the models would have to overfit to individual noisy points, which would in turn reduce the validation accuracy.
Finally, let's look at the last dataset, the one with 20% of points mixed up:
plot_synthetic_results(*datasets['global'], results['global'], '20% global noise')
Here, the impact of the noise is much more visible. The decision boundary for the model trained with the standard logistic loss got very irregular. For the second model, there is no distinct difference between this result and the previous ones. By looking at the accuracies, we can see that the second model achieved the near-perfect accuracy on the validation set relatively quickly. The model trained with the standard loss struggled to achieve this level. The performance on the train set is also worse when compared with the second model.
In conclusion, the model trained with the bi-tempered logistic loss proved to be more robust to noise than its standard alternative trained with a nonparametric loss function. The difference between the results gets bigger with the level of noise in the training data.
CIFAR-10
The previous experiment showed that by using the bi-tempered logistic loss during training, it's possible to create a model more robust to noise. The dataset we've used, however, was extremely simple. Before drawing more general conclusions, let's test the loss function on a more complex, real-world dataset.
To this end, we'll use CIFAR-10. It contains 60000 32x32 colour images in 10 different classes. The noise will be introduced by randomly changing the target label for a specified percentage of samples. Unlike the synthetic dataset, the boundary between various classes is not clear, so we will stick to the global noise only.
The dataset can be downloaded using Keras datasets module:
(X_train, y_train), (X_valid, y_valid) = cifar10.load_data()Let's verify that the dataset was correctly fetched by displaying some random samples:
plot_cifar(X_train, y_train)
Now, we'll create two noisy versions of the data - one with 10% and one with 20% level of noise:
y_train_small_noise, small_noise_idx = mix_cifar(y_train, 0.1)
y_train_large_noise, large_noise_idx = mix_cifar(y_train, 0.2)Let's display some noised samples to verify that the labels were correctly changed:
plot_cifar(X_train[small_noise_idx], y_train_small_noise[small_noise_idx])
As can be seen, the labels for the modified part of the data are now incorrect.
When it comes to training a classifier, we'll use transfer learning and ResNet50 architecture pre-trained on the ImageNet dataset. The full model is defined in the following way:
def cifar_model():
return Sequential([
UpSampling2D((7, 7), input_shape=(32, 32, 3)),
ResNet50(
include_top=False,
weights="imagenet",
classes=10,
pooling='avg'
),
Flatten(),
Dense(1024),
Dense(512),
Dense(10)
])We use UpSampling2D layer to scale the images up to 224x224 size which is native to the ResNet50 architecture. The
upsampling layer is followed by the pre-trained model without the final classification layers (this is done by
specifying include_top=False). Then, the ResNet output is flattened and passed through fully connected layers. The
output layer has 10 neurons as there are 10 classes in the dataset.
Before training, the data has to be preprocessed to suit the expected input format of ResNet. Additionally, the labels are one-hot encoded:
X_train = resnet50.preprocess_input(X_train)
X_valid = resnet50.preprocess_input(X_valid)
y_train = to_categorical(y_train)
y_train_small_noise = to_categorical(y_train_small_noise)
y_train_large_noise = to_categorical(y_train_large_noise)
y_valid = to_categorical(y_valid)The model is pretty heavy, so we will create a single instance of it. The initial weights of the model are saved to a file so that they can be later loaded to revert the model to its initial state. This is an alternative to initializing a new instance each time we want to train this architecture anew:
model = cifar_model()
model.save_weights('model.h5')Now, let's define the datasets and parameter sets we'd like to check. We define four different sets of temperatures, as it's hard to know in advance which will work best:
datasets = {'noise free': (X_train, y_train),
'small': (X_train, y_train_small_noise),
'large': (X_train, y_train_large_noise)}
temp_vals = [(1.0, 1.0), (0.8, 1.2), (0.5, 2.0), (0.2, 4.0)]We'll train the model using the standard Stochastic Gradient Descent optimizer from Keras as it's the one known to work well for ResNet. However, we have to decide on the learning rate. With the synthetic dataset, we went with the default value defined for the Adam optimizer, and it proved to work fine for both standard and parametric loss functions. Here, the dataset is much more complex, and the impact of the learning rate is likely to be more profound.
To mitigate the issue of choosing an optimal learning rate, we'll use a learning rate finder util from keraslrfinder repository. We won't go into much detail about this technique in this post, if you want to know more, check Estimating an Optimal Learning Rate For a Deep Neural Network.
Unfortunately, the newest version of the LR finder is not released to PyPI, so we'll download the sources directly from GitHub:
git clone https://github.com/surmenok/keras_lr_finder.git keras_lr_finder_repo
mv keras_lr_finder_repo/keras_lr_finder keras_lr_finder
rm -r keras_lr_finder_repoIt's now possible to import it in Python
from keras_lr_finder.lr_finder import LRFinderWe perform the learning rate search for each temperature set and on the noise-free training set:
best_lr = {}
finders = {}
for temps in temp_vals:
model.load_weights('model.h5')
model.compile(loss=BiTemperedWrapper(*temps), optimizer=SGD(momentum=0.8), metrics=['accuracy'])
lr_finder = LRFinder(model)
lr_finder.find(X_train, y_train, start_lr=1e-10, end_lr=100, batch_size=64)
lr, loss = get_best_lr(lr_finder)
best_lr[temps] = lr
finders[temps] = lr_finderThe learning rates are saved in the best_lr dictionary. Let's plot the results:
plot_lr_finding_results(finders, get_best_lr)
As expected, the learning rate grows as the temperatures diverge from the standard (1.0, 1.0). This is due to the loss
function getting flatter and flatter, thus requiring a larger learning rate to make up for lower gradients. The rates
calculated are not necessarily optimal, they simply serve as good estimates, which can save us some trial-and-error
time.
Having the learning rates estimated, we can proceed to training the model on all three datasets using different loss
functions. Both training history and the model file are saved after each training so that they are not lost in case
anything goes wrong. We train for 4000 steps, with performance metrics saved after each 100 updates. This amounts to
about 5 epochs (50000 training images, 4000 steps with batch size of 64). The reason we define steps_per_epoch instead
of defaulting to calculating performance metrics after each epoch is to have richer insight into the training process.
results = {}
for dataset_name, (X_data, y_data) in datasets.items():
results[dataset_name] = {}
for temps in temp_vals:
model.load_weights('model.h5')
results[dataset_name][temps] = {}
model.compile(loss=BiTemperedWrapper(*temps), optimizer=SGD(learning_rate=best_lr[temps], momentum=0.8), metrics=['accuracy'])
history = model.fit(X_data, y_data, validation_data=(X_valid, y_valid), batch_size=64, epochs=40, steps_per_epoch=100)
results[dataset_name][temps]['history'] = history.history
np.save(f'{dataset_name}_{temps}', history.history)
model.save_weights(f'{dataset_name}_{temps}.h5')The training process takes some time as there are 12 models to train in total. Be patient.
After the training is done, we can analyse the results. First, the models trained on the noise-free dataset. We'll plot both validation and training accuracies:
plot_cifar_results(results['noise free'], 'Noise free dataset', max_annotations=[[0.88,0.9],[0.6,0.9],[0.75,0.75],[0.75,0.5]])
We can see that models with (0.5, 2.0) and (0.2, 4.0) temperatures underperform. The accuracies didn't manage to
converge during the number of training steps we defined. When it comes to the two remaining models, we can see that the
one with (0.8, 1.2) temperatures achieved higher peak validation accuracy than the one trained using the standard
logistic loss. The bi-tempered one achieved top accuracy of 95.52%, a 1% improvement compared to 94.5% accuracy achieved
by the standard model. It's interesting to see that the parametric loss function performed better even on the noise-free
dataset.
Now, let's look at the results for the dataset with 10% noise. We'll present results for (0.8, 1.2) and (1.0, 1.0)
temperatures only, as the others proved to be inefficient:
plot_cifar_results(results['small'], '10% noise', max_annotations=[[0.52,0.9],[0.1,0.9]])
Here, we can see that, for both models, the validation accuracy managed to grow only to some point, after which it started to decrease. The training accuracies, on the other hand, kept going up. This is a typical sign of overfitting (although observed indirectly on accuracies instead of losses). As the dataset contains 10% of mislabelled samples, training accuracy above 90% implies the model starts to memorize the mislabelled data. This performance increase doesn't translate to the validation set, and impacts validation accuracy negatively. Notwithstanding, we can observe that the model trained using the bi-tempered logistic loss managed to achieve a significantly higher peak validation accuracy of 93.52% compared to 91.69% from its counterpart. This is an almost 2% relative increase in performance - definitely not an insignificant gain.
Lastly, the most noisy dataset with 20% of labels mixed up:
plot_cifar_results(results['large'], '20% noise', max_annotations=[[0.57,0.9],[0.12,0.9]])
When it comes to overfitting, the observations are very similar to the previous example. Training accuracy above 80% can be interpreted as an indication of overfitting. When models surpass this threshold, the validation accuracies tend to decrease.
As for the peak validation accuracy, again, the bi-tempered loss proved to be superior. The top accuracy of 91.74% is an almost 3% improvement over 89.16%.
Conclusions
The experiments prove that by switching the standard logistic loss to its bi-tempered version, it's possible to train models that are more robust to noise in training data. We've visualised that the tempered loss retains the ability to produce well-defined decision boundaries even for data with a significant amount of incorrect labels. This capability directly translates into achieving higher accuracies on noise-free validation sets, which was confirmed on a real-world CIFAR-10 dataset.
The analysis presented in this post is by no means exhaustive. Most likely, checking more combinations of parameters would lead to even better results. It would also be interesting to test the function using real-world examples of noise, instead of introducing it artificially in a random manner.
Summary
In this post, we've revised a parametric version of the logistic loss proposed by the Google Brain team. The new function, called the bi-tempered logistic loss, proves to be more robust against noise in data. In addition, its parametric nature allows for tuning the loss function to specific data intricacies, thus allowing for training superior, better-suited models.
If you know or suspect that your data is noisy, consider switching the logistic loss function to the bi-tempered alternative. It can be as simple as a single-line code change, and the benefits you may reap might surprise you.
